Distributed Application Management
Important: The Distributed Apps capability of deploying apps on F5 Regional Edges is in "Limited Availability".
There are multiple considerations for software development and application lifecycle - develop, build, package, deploy, secure, and operate. While developers love their development and build tools, they prefer that deployment, security, and operations be handled by someone else. This is abundantly clear with rapid adoption of cloud providers and Kubernetes.
Our goal with F5® Distributed Cloud App Stack (App Stack) has been to make it extremely easy for developers and devops teams to deploy, secure, and operate their applications using a consistent and cloud native solution across multiple sites - private data-centers, multiple cloud providers, and/or edge locations. This becomes critical when the number of sites are large or there are different underlying platforms and services. App Stack provides the following capabilities across distributed locations:
-
Deploy - Since Kubernetes is becoming the de-facto industry standard for orchestrating applications, F5® Distributed Cloud has chosen to implement its control plane with a Kubernetes compatible API for orchestration while delivering additional capabilities of managing and securing multiple clusters across distributed locations. This makes it seamless to integrate with third party tools like Spinnaker for CI/CD, etc. For packaging of microservices, we prefer Docker images, which have become another de-facto approach.
-
Secure - Multi-layer security is challenging to plan and implement. As a result, the solution provides a secure environment for applications along with security of its data, zero-trust secure connectivity, and security of its secrets (eg. passwords, keys, etc). The details of this is covered in the Security section.
-
Operate - As a fully managed cluster in every site with support for fleet management across sites, the SRE (site reliability engineering) is responsible for the lifecycle management of the clusters and the sites. There is a comprehensive system to collect logs, metrics, traces, and alerts from every customer site as well as our global infrastructure to present a unified view. The details of this is covered in the Monitoring section.
There are two scenarios where App Stack and its multi-cluster application lifecycle management will be valuable for the customer:
-
Multi-Cloud - Teams are developing in multiple cloud providers and multiple regions. The reasons for this could be features provided by a particular cloud provider, cost, administrative domains, team preference, or legacy.
-
Edge - When applications are deployed in multiple edge sites to solve latency, bandwidth or scale issues. For example, in retail locations, cell towers, factories, etc.
When dealing with multiple clusters, an operator can take different paths - it can address each cluster individually and build automation tooling for deployment, identity, metrics, logs, etc. Another approach is to deploy and manage Kubernetes Cluster Federation (kube-fed) control plane and it can make multiple physical clusters look like one cluster. Neither of these solutions provide an out-of-the-box and complete application platform for managing multiple clusters as a fleet while removing the need for doing custom tooling, operating control planes, and integrating with other products to solve problems of identity, connectivity, security, etc.
F5 Distributed Cloud Services provide a tenant with a representative application cluster where customer deploys their applications and based on configuration our distributed control plane will replicate and manage them across multiple sites. In addition to containerized applications, the platform also provides the ability to manage virtual machines.
Virtual Kubernetes (vK8s)
F5 Distributed Cloud Services support a Kubernetes compatible API for centralized orchestration of applications across a fleet of sites (customer sites). This API is “Kubernetes compatible” because not all Kubernetes APIs or resources are supported. However, for the API(s) that are supported, it is hundred percent compatible. We have implemented a distributed control plane within our global infrastructure to manage scheduling and scaling of applications across multiple (tens to hundreds of thousands of) sites, where each site in itself is also a managed physical K8s cluster.
Pods and Controllers in vK8s
The core concept in application management on Kubernetes is a Pod. Pod is the basic and smallest execution unit that can be created, deployed, and managed in Kubernetes. A Pod consumes compute, memory, and storage resources and needs a network identity. A Pod contains single or multiple containers but it is a single instance of an application in Kubernetes. More details about Pods can be found at Pod Overview. In the case of vK8s, we also support scheduling of Virtual Machines as a Pod to ease brownfield deployment.
Horizontal scaling of application is done by running multiple instances of an application. Kubernetes calls this replication and each instance of the application is a Pod. To create, deploy, and manage multiple Pods as a group, Kubernetes has an abstract concept of Controllers. Controllers can automatically create multiple Pods, providing replication, they can detect when a Pod goes down and relaunch a new Pod, providing self-healing capabilities and perform different strategies for deploying or rollout of Pods. Deployment, StatefulSet, and Jobs are concrete implementations of Controllers in Kubernetes.
A detailed explanation of the basic Kubernetes concepts can be found at Kubernetes Concepts.
Objects and APIs in vK8s
Kubernetes Objects and APIs
Virtual Kubernetes supports the following Kubernetes objects. All these objects have additional capabilities around virtual-sites for distributed application management. The vk8s control plane is responsible for ensuring that the desired state for the object is achieved and instructs the local control plane on each individual site to achieve its computed state.
-
Deployments - Deployment is a Controller for stateless applications like web-servers, front-end web-ui, etc. More details about Deployment can be found at Deployment Overview.
-
StatefulSets - StatefulSet is a Controller for stateful applications like databases, etc. More details about StatefulSet can be found at StatefulSet Overview.
-
Jobs - Jobs is a Controller for run-to-completion type of applications like a shell script, database defragmentation job, etc. More details about Jobs can be found at Jobs Overview.
-
CronJob - A CronJob creates Jobs on a repeating schedule similar to a crontab (cron table) file. More details about CronJob can be found at CronJob Overview.
-
DaemonSet - A DaemonSet is used to run a copy of a Pod on all or some Nodes. DaemonSet are only supported on customer sites. More details about DaemonSet can be found at DaemonSet Overview.
-
Service - Applications need to communicate with other applications to perform their tasks. To communicate with other applications, they need to be discoverable and exposed as a network service. Service is a concept in Kubernetes that is used for this purpose. Service is used to select a set of Pods and define a network access policy for them. More details about Service can be found at Service Overview.
-
ConfigMap - Applications need to be configured based on the deployed environments to allow generic application images to be used and for an application to be portable. Kubernetes exposes ConfigMap for this purpose. ConfigMap can be used by Pods for this. More details about ConfigMap can be found at ConfigMap Overview.
-
Secrets - Sometimes applications need access to sensitive information like certificates, tokens, etc. Instead of bundling these inside application image or putting them inside Pod definition, Kubernetes allows users to create a Secret to manage these. More details about Secrets can be found at Secrets Overview.
-
PersistentVolumeClaim - Stateful applications like databases sometimes need access to storage resources whose lifecycle is independent of the lifecycle of Pods and out-live even the application. Further, different applications may need access to storage with different access, latency, and capacity requirements. To abstract out the details of storage implementations, Kubernetes has a concept of StorageClass. For an application to consume storage resources, it needs to be provisioned by the cluster administrator. To separate out the provisioning and consumption of storage resources, Kubernetes exposes the concepts of Persistent Volume which is used for provisioning storage, and Persistent Volume Claim that is used by Pods to consume storage resources. More details about the Persistent Volume APIs can be found at Persistent Volume Overview.
-
ServiceAccount - A service account is used to provide identity for processes running in a Pod. More details about Service Account can be found at Configure Service Account.
-
Role - Role contains rules that represents set of permissions. Permissions are purely additive and there are no deny rules. More details about Role can be found at RBAC Authorization.
-
Role Binding - A role binding grants the permissions defined in a role to a user or set of users. It contains list of subjects (users, groups, or service accounts) and the role being granted. More details about Role Binding can be found at RBAC Authorization.
Details on creation of Virtual Kubernetes object and its parameters is covered in the API Specification
Workload Object and API
Workload is used to configure and deploy a workload in Virtual Kubernetes. A workload may be part of an application. Workload encapsulates all the operational characteristics of Kubernetes workload, storage, and network objects (deployments, statefulsets, jobs, persistent volume claims, configmaps, secrets, and services) configuration, as well as configuration related to where the workload is deployed and how it is advertised using L7 or L4 load balancers. A workload can be one of simple service, service, stateful service or job. Services are long running workloads like web servers, databases, etc. and jobs are run to completion workloads. Services and jobs can be deployed on customer sites. Services can be exposed in-cluster or on Internet by L7 or L4 load balancer or on sites using an advertise policy.
Following are the different types of workloads:
-
Simple Service - A service with one container and one replica that is deployed on all customer sites and advertised on the Internet using a HTTP load balancer. A service will create a corresponding Kubernetes Deployment, Service, and optionally ConfigMap and PVC objects. It will also optionally create an HTTP or TCP load balancer object.
-
Service - A service with one or more containers with configurable number of replicas that can be deployed on a selection of customer sites and advertised within the cluster where is it deployed, on the Internet, or on other sites using TCP or HTTP or HTTPS load balancer. A service will create a Kubernetes Deployment, Service and optionally ConfigMap and PVC objects. It will also optionally create an HTTP or TCP load balancer object.
-
Stateful Service - A service with individual persistent storage given to each replica. A stateful service will create Kubernetes StatefulSet, Service, and optionally ConfigMap objects. It will also optionally create an HTTP or TCP load balancer object.
-
Job - A run to completion task with one or more containers with configurable number of replicas that can be deployed on a selection of customer sites. A job will create Kubernetes Job, and optionally ConfigMap and PVC objects.
Namespaces
As mentioned in the Core Concepts section, F5 Distributed Cloud Services provide every tenant with the capability of creating many namespaces within a Tenant.

Figure: Multiple Namespaces within a Tenant
In a physical Kubernetes, it is possible to create “virtual clusters” called namespaces. However, in case of F5 Distributed Cloud Services, we already provide the capability of many namespaces per tenant and there is no capability to create another set of namespaces within vK8s. As we will cover in the next section, within each Namespace, the user can create an object called vK8s and use that for application management.
Virtual Site Capabilities
Virtual Kubernetes (vK8s) object can be configured under a namespace and only one such object can be configured in a particular namespace. vK8s object has a reference to the virtual-site which selects the sites on which the application can be deployed, secured, and operated. The virtual-site reference of vK8s is used as the default virtual-site for the given vK8s. When a vK8s object is created, the following things happen:
-
URL for vK8s API is activated upon creation of the vK8s object
- The URL will follow the pattern:
/api/vK8s/namespaces/<namespace>/<vK8s-name>/<kubernetes-api> - vK8s API URL uses the same credentials as those used for access to to F5 Distributed Cloud Services APIs
kubeconfigfile for access to the vK8s API can be downloaded by logging into F5® Distributed Cloud Console (Console).- Standard upstream
kubectlCLI tool can be used on the vK8s API URL or the downloadedkubeconfigfile can be used to access the vK8s APIs
- The URL will follow the pattern:
-
Based on the default virtual-site provided, for each of the sites in the virtual-site object:
- Namespace is created (same as namespace of vK8s object prefixed with the tenant of the vK8s object) in the site
- Isolated namespace specific virtual network on the site
- If this was first vK8s selection for the tenant on the site, then an isolated service virtual-network is created
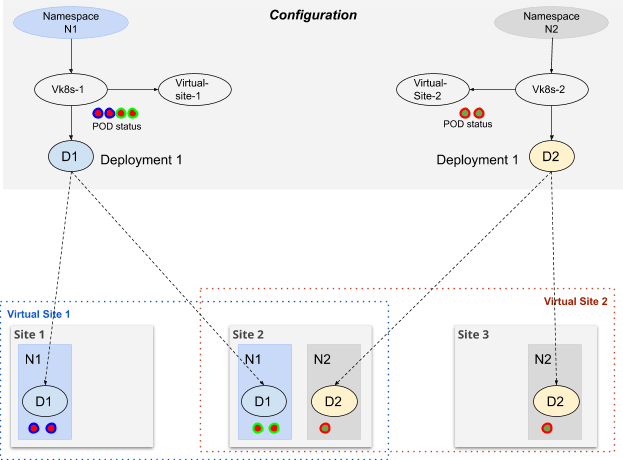
Figure: Depolyment Using vK8s
When an object (deployment, job, services, etc) is created using vK8s APIs, that object is instantiated on each site in the given namespace of the vK8s objects for all sites selected (in the virtual-site). Status of these objects from each site is collected and available on vK8s API.
As an example consider that a Deployment - deployment1 is created in vK8s. Once the Deployment is created, then it is instantiated on site selected by virtual-site. If the Deployment had Replicas of 3 and this Deployment was created on 3 sites (site1, site2 and site3), on each site 3 Pods will be created. vK8s API will show the status of all the Pods instianted for the Deployment across all the sites. The List Pods API on the vK8s API will report 9 Pods and each Pods’s Node will show the Node and site on which the Pod exists.
NAME STATUS NODEdeployment1-6fffd6f5b7-7nkfh Running site1-node1deployment1-6fffd6f5b7-86vqt Running site2-node3deployment1-6fffd6f5b7-8mcww Running site1-node2deployment1-6fffd6f5b7-drmnf Running site3-node1deployment1-6fffd6f5b7-hc72v Running site2-node2deployment1-6fffd6f5b7-jpt5s Running site2-node1deployment1-6fffd6f5b7-mrprr Running site1-node3deployment1-6fffd6f5b7-p2xz6 Running site3-node2deployment1-6fffd6f5b7-q5grm Running site3-node3By default, the Deployment is instantiated on all sites configured in the default virtual-site configured on the vK8s object. However, consider the following use case:
-
In given namespace, we may want Deployments in different virtual-sites. For example, Deployment D1 is instantiated in virtual-site-1 and Deployment D2 is instantiated in virtual-site-2
-
Once Deployment D1 is instantiated in virtual-site-2, upgrade of deployment D1 may be required on only certain sites within the virtual-site-2.
Deployments created on a vK8s API can be instantiated either on the sites selected by the default virtual-site or a list of virtual-sites can be provided as Annotations to the Deployment to solve the above use-case. The format of the Annotation is:
ves.io/virtual-sites: “<namespace>/<virtual-site-name>,..”As an example the below annotation:
ves.io/virtual-sites:“namespace1/virtual-site-1, shared/virtual-site-2”will take the union of sites from virtual-site-1 and virtual-site-2 and create Deployments on each of these sites.
To solve advanced deployment use-cases, concept of Override is used. Override is a Custom Resource Definition (CRD) in vK8s. The CRD is defined as a resource that has a list of sites and associated DeploymentSpec.
{site_list: [site1, site2, site3, ..]deployment_spec = {}}Deployment has an annotation for Override, which is an ordered list of override CRD(s):
{ves.io/overrides : “overrideCRD1, overrideCRD2, …”}When an Override is applied to a Deployment, for sites within the Override site_list original Deployment Spec is ignored and Override Deployment Spec is applied. This allows small set of sites to be experimented with. The user can change software-image, labels, limits, storage and other Deployment Spec parameters in Override.
Override mechanism can also be used to implement canary or A/B feature testing across a fleet of sites:
- For Canary version testing - small set of sites is selected and software version is upgraded on these sites using override. Once all the verification is done, the same software image can be upgraded in the original deployment and override is deleted.
- For A/B feature testing - a small set of sites selected and software version is upgraded on these sites using override. Collect metrics to analyze the behaviour of the feature and once the verification is done, take appropriate decisions to upgrade the original deployment.
The above discussion for Deployment applies to other Kubernetes objects as well.
Managing Compute Resources for Containers
Each container in a Pod consumes compute resources - CPU and memory(RAM). All containers launched using the vK8s APIs have limits on the compute resources. Memory is measured in unit of MiB (mebibyte), power of 2. One MiB is 1,048,576 bytes. CPU is measured in unit of vCPU. Each vCPU is a thread on a CPU core. vK8s uses the concept of Workload Flavors to help in the setting, managing, and accounting of compute resources for containers. Workload Flavors are pre-determined combination of CPU and memory that can be selected on a per Deployment, Job, and StatefulSet and apply to each container created by these controllers. Workload Flavors are analogous to Amazon EC2 Instance Types. The following standard Workload Flavor types are supported:
| Flavor Name | CPU (in vCPU) | Memory (in MiB) | Notes |
|---|---|---|---|
| ves-io-tiny | 0.1 | 256 | Use the ves-io-tiny annotation for the deployments that are not resource intensive. |
| ves-io-medium | 0.25 | 512 | Use the ves-io-medium annotation for the deployments that consume resources moderately. |
| ves-io-large | 1 | 2048 | Use the ves-io-large annotation for the deployments that are resource intensive. |
{ves.io/workload-flavor : "ves-io-medium"}By default if no ves.io/workload-flavor annnotation is present, then vK8s will use the compute resources from the ves-io-tiny flavor.
The Workload flavor CPU and memory map to the Kubernetes containers resources limits. Kubernetes containers resources requests are set to 25% of the CPU limits and 50% of the memory limits.
For example, for ves-io-tiny workload flavor the CPU requests will be 0.025 vCPU and memoryrequests will be 128 MiB.
resources: limits: cpu: 100m memory: 256Mi requests: cpu: 25m memory: 128MiThe annotation ves.io/workload-flavor takes effect only on F5 Distributed Cloud Services Global Network. In case of vK8s deployments on user's cloud (public or private) or user's edge App Stack node, the resource definition in the user's deployment file is honored.
Pod Networking
When the Pod (VMs or Containers) is created on a particular site (single or multiple nodes), it will get an interface on the namespace network that is completely isolated from other namespaces and every namespace network uses the same subnet range.

Figure: Network Connectivity and Communication for Pods
The leads to the following situation:
- Application Pods in the same namespace can communicate with each other
- Application Pods from one namespace cannot communicate with other namespace
- Application Pods can communicate to site-local and site-local-inside networks using source NAT (SNAT)
Network policies can be configured within a namespace and are applied to traffic within the namespace-network allowing segmentation of traffic within a namespace.
If an application in namespace-1 wants to communicate with another application in namespace-2, that is only possible if the application in namespace-2 has a service defined in K8s that can be accessed by pods in namespace-1.
Services
Services are a mechanism to create a proxy that can expose a service provided by an application to other applications within a namespace or across namespaces
Local Services
Adhering to the default behavior of Kubernetes, Services are automatically “Site Local” in scope and all namespaces (of the tenant) can access services. “Site Local” means that only pods within a site (in case of multiple nodes in a site) can access services within that site, and not across sites.
Service policies can be configured in a namespace and are applied to services within the namespace, allowing application level segmentation of traffic.

Figure: Accessibility for Site Local Services
External Services
For any inter-site or external (eg. public internet, applications not managed by vK8s) access of services, there needs to be a virtual-host configuration that uses the services defined in K8s as endpoints and advertise-policy to expose the services in other sites. In case of services being exposed across sites, the F5 Distributed Cloud Fabric gets used for inter-site traffic

Figure: Accessibility for Inter-Site and External Services
Using Kubernetes services configuration on vK8s combined with additional configuration of objects like virtual-host, service policy, application firewall, etc - applications can be exposed across sites or even be exposed on the public Internet.
vK8s uses the concepts of default virtual-sites, virtual-site annotation for the K8s workload resources, and override CRD for controlling the deployment, operation, and securing of applications on sites or grouping of sites. vK8s provides a mechanism for supporting various deployment strategies like blue-green, canary, A/B testing, etc. across sites for the edge-computing use case and across clouds for the multi-cloud use case.